




 Qzone
Qzone
 微博
微博
 微信
微信
在金融机构的日常运营中,有一类资产无处不在,却长期沉睡——以PDF为代表的非结构化文档。征信报告、授信材料、合规函件、审计底稿……这些文档的设计初衷是“给人看的”, 但数字化系统需要的,是“给机器用的数据”。
如何让计算机真正“读懂”这些文档,提取出风控、营销、合规系统可直接使用的结构化信息?这是金融数字化转型的关键堵点。
过去,企业尝试过规则引擎、模板匹配、传统OCR,但面对格式多变、内容复杂的金融文档,这些方法往往力不从心。
通用大模型虽能理解语义,但训练专属模型成本高、周期长、数据敏感。有没有一条更务实的路径?福昕IDP(智能文档处理中台)的答案是:不靠“海量数据喂养”,而用“业务知识引导”。
三位一体:AI大模型 + 业务模型 + 文档大数据的智能范式
福昕IDP开辟了一条全新的“知识炼金”路径——它不是一个单一工具,而是一个集文档应用、开发、运行于一体的一站式平台。
其核心逻辑在于,将“AI大模型”的通用智能,与具体的“业务模型”相结合,作用于海量的“文档大数据”之上,完成从“图像→文字”、“文字→数据”再到“数据→知识”的完整蜕变。
这套组合拳的核心能力体现在三个层面:
DAC(内容解析与转换):让计算机像人一样理解PDF的结构与语义,输出结构化的JSON或Markdown数据,为后续处理打下基础。
SDE(结构化数据提取):基于用户自定义模板,从大量同质文档中定向、精准地“淘”出所需数据。
KBM(智能可信知识库):基于文档,低成本、高效率地构建领域知识库,实现知识的智能化检索与应用,让沉睡的文档真正“开口说话”。
业务场景示例:银行如何高效提取征信报告关键信息?
某银行建设新一代个人信贷风控系统,需从PDF版征信报告中提取以下信息:姓名、证件号、就业状态、个人查询次数、欠税记录、强制执行记录、民事判决、行政处罚、近5年逾期月份数等。
这些报告来自不同机构,版式各异,人工处理费时费力。
通过福昕IDP-SDE,银行只需三步:
定义数据模板
在系统中配置字段规则(如“就业状态”可能出现在“工作信息”或“职业状况”区域);
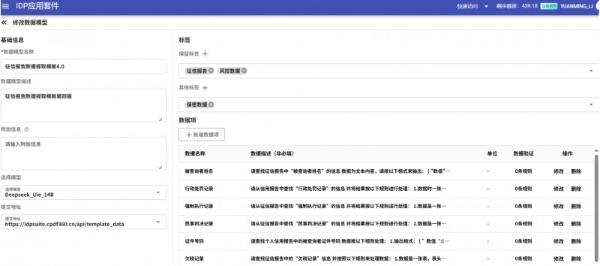
提交PDF文档
系统自动识别、理解业务模板,自动解析PDF内容,基于规则和语义理解文档信息,定位目标信息;
输出结构化结果
以标准JSON格式返回,直接对接风控数据库,支撑自动化评级与预警。

数据提取结果示例图
从征信报告到信贷审批,从合规检查到监管报送,只要存在“给人看的文档”与“给系统用的数据”之间的鸿沟,福昕IDP就能架起一座智能桥梁。
在大模型时代,真正的智能在于能否把AI与业务知识真正融合。福昕IDP所做的,正是唤醒那些沉睡在PDF中的沉默资产,将其转化为可计算、可行动的决策要素。


















 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>
























